吉隆坡-兰卡威之行简版攻略















地点:陕西安康的老家餐桌上
设备:一台已经用了 5 年的 Air M1(Oh fuck,这电脑真耐用!)
好久不见,各位!由于个人原因,最近 1、2 年博客一直没有更新,在此向大家道个歉。趁着新春佳节,大年初一把 2024 年的年终总结补上。2023 年的时候,我甚至忘记写个人总结,不过也没关系。
这两年里,我找到了人生挚爱,即将步入婚姻,工作也早已步入正轨。但在技术方面,尤其是前端方向,我已经失去了探索的动力。这是因为整个前端行业已经进入了所谓的“停滞期”,所以我衷心希望大家尽早考虑转行,而新人也不建议学习前端。
小时候,我特别喜欢一款游戏——QQ 飞车,所以在 2024 年回归了这款游戏。此外,我还经常和小 P 一起玩双人游戏,甚至经常玩到半夜。早知道这样,我应该早点买 Windows 电脑了!
为了更好地白嫖飞车道具,我甚至写了脚本自动签到,还利用 AutoIt 脚本 + 小米智能插座,让电脑每天半夜自动执行飞车任务,因为这样可以获取极品道具。为了玩游戏,我也是拼了。不过,当我终于得到小时候梦寐以求的赛车时,那种惊喜感已经没那么强烈,反而慢慢变得索然无味。(至今还是舍不得氪 S 车,毕竟 2K 的价格,我的消费观完全不支持我一下子冲这么多钱到游戏里,太疯狂了!)
最近 1、2 年的工作方向仍然是 前端(React),没办法,为了生计。不过,在这两年里,我对 大型 React 项目 有了更多的思考,写代码时也会更加注重架构和性能优化。
在业余时间,我可能会实现一些 随时想到的功能(feature),但由于时间原因,通常都会搁置。比如,前段时间开源的 YourPanel 项目,后续还会继续做。但由于 Rust 水平有限,目前暂时停滞。
最近,我在帮一个老朋友 免费做 PM 的工作。下班后还要搞到 11 点,整理需求、安排程序员工作任务,说实话真的很累。做 PM 不比程序员轻松,但能学到很多东西。我愿意做 PM,是因为想补足自己在 业务逻辑 上的短板,提高 业务串联能力。不过,做了这么久 PM,貌似这个问题也没有彻底解决?等 2025 年再看看吧。如果有效,那么免费也是值得的,只是有点累……
这一年,我学习 Rust 的时间比前几年更多,练手项目是 Rustlings。这个项目对新手非常友好,主要是一些 test case,程序员需要修复 Rust 编译错误,每个错误都归类到不同的章节。如果遇到困难,还有对应的错误解析,帮助你修复代码,完成后会很有成就感。
强烈推荐 刚入行的程序员或有经验的前端开发工程师学习 Rust!虽然我已经学了 “好几年”,甚至学了 “很多次”,但目前依然远远算不上入门。
和小 P 养了一只狗,叫 粽子,是一只超级可爱的柯基!有空会 PO 到博客里,给大家当电子宠物看。
希望大家 好好保重身体!我今年年龄不大,但已经出现了一些心脏问题,有时候会有一点心悸,不过是偶然发生的。而且我从不加班,可能是因为有时候遇到烦心事导致的。
最近 2 年生病特别多,给大家举几个例子,大家平时可以多留意:
今年 4 月份计划去蜜月旅行,准备和小 P 去 马来西亚,希望能好好放松一下心情,也许对心悸有所改善。
最近一段时间特别讨厌微信,所以我准备学习一段时间 逆向,Hook 微信,开发一个微信 API,把消息接入到 TG(Telegram) 进行处理。预计会有相关的开源作品,如果逆向顺利的话,我就能彻底摆脱微信了!这块会单独写一篇文章聊聊我的想法,项目暂定名为:“逃离微信”。
另外,还计划继续学习 Rust,上面的 “逃离微信” 项目就打算用 Rust + Python 实现,希望能有所收获。此外,我还计划写一个 Rust HTTP API 框架 作为练手项目,接下来继续完善 YourPanel 开源项目。
Flag 立了这么多,希望 2026 年不会发现一个都没实现,那就太尴尬了!
最近博客服务器要换了,不再付费使用 阿里云国内VPS,老朋友友情赞助香港VPS一台~
前段时间,和群友偶然聊到了GUI话题,期望可以使用GUI应用来替代前端工具,比如代码规范/校验等,但是查找了相关资料,关于代码管理类的GUI程序非常少(甚至说是一个空白),总结了以下大概有以下几点:
如果你是Mac用户,相信你一定知道RayCast,RayCast本质上是一个代替Mac启动器的应用程序,但是由于其强大的插件机制,可以让前端开发者方便地开发各种插件,比如翻译/词典/截图等等,如下图是我安装的一款颜色选择器插件:
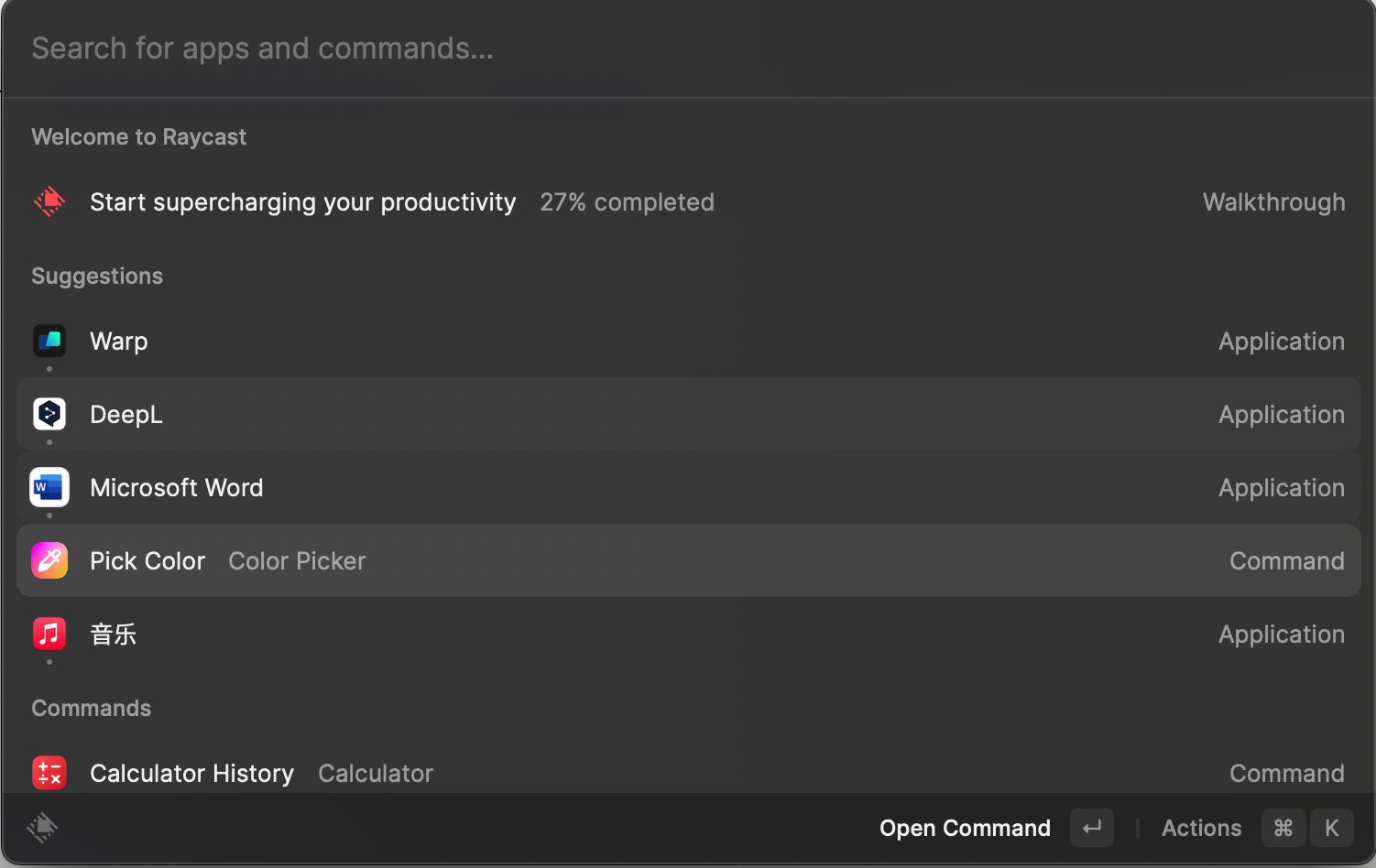
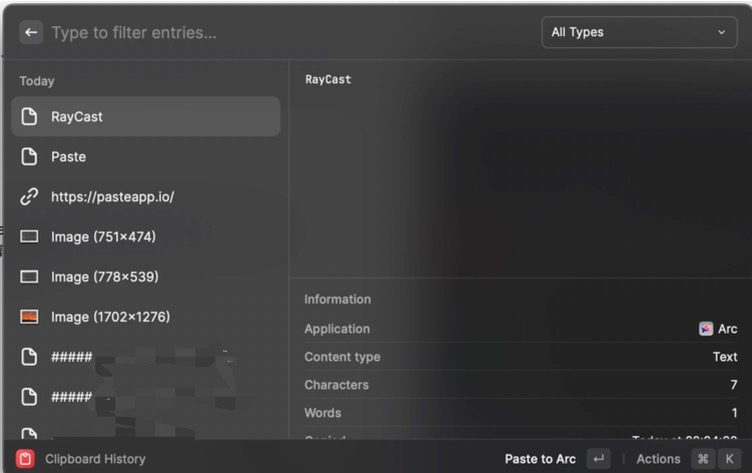
RayCast的最佳设计不仅限于此,它还提供了‘快捷键’功能,使其通过预定义好的快捷键,轻松的唤起用户装的指定扩展,例如在Mac中有一款大名鼎鼎的剪贴板软件叫作Paste,而在RayCast中可以直接免费的使用类似的功能,装好指定的插件之后,只需要快捷键就可以唤出剪贴板软件:
另外,有曾接触过运维的同学们应该都知道一个国产的面板应用“宝塔”,虽然这款软件面向的是初级运维人员,但是其免费易用的特性让不少非专业的开发人员也能管理服务器。比如本博客就在使用宝塔软件,是我在上高中时使用宝塔搭建的,已经运行有5,6年了。抛开安全问题,作为一个在当时不懂运维的同学也能深深产生依赖,一直沿用至今,这或许就是GUI的魅力。
读者们对于GUI程序并不陌生,我们在使用的Mac,iphone等操作系统都在时时刻刻的服务用户;同样我们开发者领域也有一些出色的GUI程序,比如Clashx,SourceTree帮助着我们日常开发。
但是有没有一款工具可以改变开发习惯,真正的提高效率,并且兼顾安全。拿前端领域举例,诸如Eslint等工具层出不穷,包管理工具也是五花八门,而且作为一名优秀的开发者无时无刻都在使用工具去减少重复劳动,我们需要有大量的额外工具,例如JSON校验,Mock服务,Local Server,甚至是代码优化,日报/日志工具。
很遗憾,我们目前并没有这样的软件去集成这些五花八门的工具,但是读者们会心里想,我可以唤出浏览器打开一个工具网站就可以解决所有问题,为什么还需要一个GUI软件去做这样的事情呢?这也是本篇文章的重点。
NPM对于前端开发者来说并不陌生,我们想要安装一个库其实要做很多调研,大多需要查看其更新时间,下载量以及issue数量等等;但是当你有一天想要开发Rust程序时,你并不知道你要编写的功能需要安装什么库,你也不知道库和库是如何依赖的,这势必要浪费很多时间,所以如何统一各个语言的依赖管理呢?
这里实现技术也比较简单,无非就是将用户所期望的依赖底层通过命令行的形式进行安装;GUI的重点是如何查找到开发者心仪的依赖,下图是使用NPM搜索PDF关键字的结果:

在默认搜索模式下,在搜索如此具体的关键字时,仍然找不到pdf.js的核心库,如果我是一个对前端领域比较陌生的开发者,我大概率会安装第一个依赖。虽然举得这个例子有点极端并且有一点杠精,但是作为一款跨平台的代码项目管理工具,我们要做的是多个流行语言的包管理工具,对于经常跨语言开发的开发者,你不再需要打开多个标签页并且你也不需要熟悉你安装依赖的命令,只需要2步:
如果在依赖列表中看到了你已安装的依赖,你完全可以双击右键去卸载它,这在我们频繁查找与安装依赖的场景非常有用,并且节约时间。
另外依赖检索列表中,会借鉴NPM的搜索模式,并且在之上结合搜索引擎和ChatGPT,会给你一个智能的依赖推荐,尽管你搜索的关键字和实际的依赖完全不同,你也能快速安装它!并且智能推荐是联网的,你无需GPT4,软件内部会将搜索引擎的结果提供给GPT,让GPT提取可用的依赖信息。
代码体检的功能是一个仍然在探讨的feature,所以本章和最后完成的功能差距可能会非常大。在一些代码管理的SASS产品中,可能会提供这种功能,并且相对耗时以及昂贵。那么我们如何做这个功能呢?当代码项目被添加到软件中时,会经过一次极快的预处理,会在短时间内得出项目的技术栈和依赖关系,基础的模块数量。
在真正体检时,会得出一份报告,这个报告生成的过程不会产生联网的请求,一切都在本地完成,不依赖GPT。因为大额的代码段落让GPT分析会造成很多Token消耗,这一般人不太用得起(笑哭)。所以这块可能会使用开源的一些检测工具去扫描代码库中可能重复的函数,并且行数特别多的函数,并且注释的数量多少也会影响报告分数;
报告中的检查项可以手动关闭,因为开发者的习惯并不一样,有些人并不习惯编写注释,也有一些项目避免不了行数过多的函数。如果关闭对应的检查项,软件也会跳过这些步骤,势必会更快地生成报告。
软件会提供一个基础的工作流,将软件项目和快捷键绑定,甚至和其他软件绑定。你可以理解为迷你版的快捷指令,可以用代码编写工作流中的代码,比方说你有一个很重很大的项目,当你有一天重启了电脑或者应用崩溃闪退,导致你不得不重新打开这些应用。那么你就可以自定义一个工作流,当你使用快捷键唤出项目时,你的数据库,Docker,Redis就全部按照你的指示有顺序的跑起来了!
另外当你编写代码时,软件会每隔一段时间去检测你正在编写的模块,找到你经常更改的代码块,并且自动的给出你优化的建议(会有一个提示消息,和Copilot不同)。
利用到GPT的地方会有很多,比如当您把代码提到暂存区时,软件就已经分析其代码并且对代码做总结,生成好commit message,你只需要看到消息之后,点击确定,就可以应用这个提交。
除了显性的工作流之外,在软件内部,不管是体检的预处理分析文件还是你在编写代码时候产生的输出,都有可能会给软件其他功能提供支持。比如日志/日报插件,它会总结你一天的Commit message和具体的工作任务,你可以为其定义一个日报模板,只需要稍加修改,就可以一键发布;发布到哪儿呢?Github/Gitlab/钉钉,只要存在第三方接口的应用,自己编写逻辑,就可以直达!
还记得一个成功的软件核心是什么吗?就是插件,软件可以允许用户使用HTML/JS定义界面,使用Rust/WASM去定义其实现,关于支持Nodejs?这个得看后续啦。
插件分为2类:
这是借鉴了Obsidian,对第三方插件必须要提供源代码并且接受监管,如果对于非常流行的第三方插件会合并到官方插件中,但是会继续由社区开源爱好者(和官方开发者)一起推动维护。
有了第三方插件,你脑海中的各种工具,比如JSON校验,Mock服务,Format等等,把那些工具网站都删除了吧~,只需要一个快捷键就可以抵达的插件,无论是性能还是便捷性,本地的软件都会更胜一筹。
对了,软件的名字叫作YourPanel,现已开源:
https://github.com/yourpanel/core (Next.js + Tauri)
文章中的GPT相关功能,都可以关闭,关闭这些GPT调用之后,任何有网络连接的插件在运行时,都会让你知晓;并且在安装插件时,你也可以清楚地看到插件是否基于网络连接!
作为一个本地的代码管理面板软件,我期望你的代码只允许你一个人访问,并且期望用较少的网络连接去完成任务。在初期使用中,我们没有计划引入用户管理,这意味着软件没有登录,我们也看不到你的代码和你的任务。
我们的初心就是:在一个安全环境下,提供开发者便捷服务。
久别重逢,最近换了新工作,三个月很忙碌,以后博客会定期更新;前几天Vue发布了3.3,我今年没写过Vue,但是也关注Vue的进展,总的来说Vue的发展方向在version 3这个版本中基本稳定了,反而DX的设计上会越来越好,如果你不使用Typescript,那么Vue3的许多新特性你可能并不适用,今天我们简单看一下Vue3.3的内容。
在之前的setup语法糖里面,如果要声明组件名称等组件属性,需要再写一个script标签,这会给新手和Vue2 -> Vue3的用户带来困惑,并且会给Eslint/Volar带来一定的难度,现在可以使用defineOptions宏来指定这样的信息,但是defineOptions不允许指定props/emits,因为这两者可以使用其他宏指定。
<script setup lang="ts">
defineOptions({
name: 'HelloWorld',
})
</script>这是一个很旧的问题,在使用defineProps时,是不能从其他地方引入类型使用的,可以具体查看RFC。在这个版本将支持从其他类型文件中导入,比如这样:
<script setup lang="ts">
import type { Props } from './foo'
defineProps<Props & { extraProp?: string }>()
</script>只不过目前并不支持复杂的类型操作,在之前我们使用defineProps做类型声明时,如果传入了类型,编译器将会将类型转换为运行时代码;而现在如果要支持外部的类型要么就调用Typescript的龟速编译器,要么就自己实现一个基础的编译器,让其识别到导入的“是什么类型”。目前Vue采用了第二种方案,并且支持一个复杂类型的例子(如上代码所示)。
简化了父组件和子组件双向通信(v-model)的代码,比如在以前我们编写v-model相关逻辑,需要写这么多代码:
<script setup lang="ts">
const props = defineProps<{
modelValue: number
}>()
const emit = defineEmits<{
(evt: 'update:modelValue', value: number): void
}>()
emit('update:modelValue', props.modelValue + 1)
</script>现在使用defineModel:
<script setup>
const modelValue = defineModel<number>()
modelValue.value++
</script>在复杂场景下,有时候Volar并不能准确推导组件类型,或者有时你想自定义组件的slot类型,可以使用defineSlots:
defineSlots<{
default(props: { item: T }): any
}>()<HelloWorld :data="['foo', 'bar']">
<template #default="{ item }">{{ item }}</template>
</HelloWorld>这对于普通组件来说意义不大,但是对于带有slot的复杂组件来说很有用,意味着可以自动推断传入的类型,在组件中使用,比如以下的场景:
<script setup lang="ts" generic="T extends string | number, U extends Item">
import type { Item } from './types'
defineProps<{
id: T
list: U[]
}>()
</script>T和U都可以被用作emit/ts代码逻辑中,它和defineSlot在一起用最好
Vue3在之前在编译sfc的template时,会将静态内容提升,这样在大型项目中重复的静态内容会用这样的优化手段会得到提升,可以看一下之前的Vue文章。但是现在在setup中,也支持这样的优化了,如果在script中编写了基础数据类型(除了Symbol)的变量,都会被提升到顶部。这个改进主要解决了之前的问题,比如defineProps时,只能使用字面量:
<script setup>
const hello = 'world'
defineOptions({
hello,
})
</script>这样的代码在之前是会有编译错误的,现在不会了,原因是defineProps宏编译之后,会变成下面的代码:
const __sfc__ = {
props: [propName],
setup(__props) {
},
}显然这是错误的,无法访问到propName,经过提升优化之后,将会解决这个问题:
const __sfc__ = {
propName: "hello",
props: [this.propName],
setup(__props) {
},
}(伪代码)
同样的,这次改进主要是少写一些代码:
const emit = defineEmits<{
(e: 'foo', id: number): void
(e: 'bar', name: string, ...rest: any[]): void
}>()现在可以这么写:
const emit = defineEmits<{
foo: [id: number]
bar: [name: string, ...rest: any[]]
}>()如下代码所示,这更好的提供props的默认值:
const { msg = 'hello' } = defineProps(['msg'])
此时,msg仍然还是一个响应式变量,并且如下代码可能也不会再需要了:
export interface Props {
msg?: string
labels?: string[]
}
const props = withDefaults(defineProps<Props>(), {
msg: 'hello',
labels: () => ['one', 'two']
})在此前经常使用withDefaults宏去提供props默认值,现在有更好的趋近于es6的写法,所以建议大家之后可以使用这个功能,但是这个功能是实验性质的,需要自行斟酌。
今天我们简单聊一下Typescript5带来了什么,因为最近开源工作的需要,对于其装饰器的实现好奇,今天就去着重学习了一下。但是这篇文章其实并没有什么深度和内容,时间紧迫,我最近在适应新的工作环境以及Sword.js 2.0开发,这段时间的文章可能间隔时间会很长,话不多说,言归正传。
在ts最新的版本中对(还在ecma stage-3阶段)装饰器最新的提案进行了实现,在我们之前使用ts时也偶尔使用装饰器,但是之前ts实现的装饰器版本是比标准tc39的更早(实验性质),所以我们不得不在tsconfig.json去打开实验性装饰器的开关(experimentalDecorators):

否则我们的代码会报错,在未来,这个配置仍然会继续存在,假如没有这个配置,那么现在装饰器的语法将是有效的,不会报错。但是无论是类型检查和tsc,新旧装饰器会有很大不同,尽管我们可以编写装饰器去兼容新旧装饰器,但是如果是老版本的代码,这样做不是一个明智的选择。
新的装饰器不支持装饰参数,希望未来ecma标准会支持这一行为:
class Person {
@required
name: string;
constructor(name: string) {
this.name = name;
}
greet() {
console.log(`Hello, my name is ${this.name}.`);
}
}下面我们可以编写一个装饰器函数,比如在一个函数中添加输出前和输出后的语句:
function loggedMethod(originalMethod: any, _context: any) {
function replacementMethod(this: any, ...args: any[]) {
console.log("LOG: Entering method.")
const result = originalMethod.call(this, ...args);
console.log("LOG: Exiting method.")
return result;
}
return replacementMethod;
}为了便于理解,2个参数都暂时使用了any,可以看到第一个参数为originalMethod代表了原method,第二个参数context代表了上下文。在装饰器函数中我们返回了一个新的函数去代替,像下面一样使用装饰器,就可以得到一个输出前和输出后的功能:
@loggedMethod
greet() {
console.log(`Hello, my name is ${this.name}.`);
}有时候,我们也可能这样调用一个方法:
class Person {
name: string;
constructor(name: string) {
this.name = name;
}
greet() {
console.log(`Hello, my name is ${this.name}.`);
}
}
const greet = new Person("Ray").greet;
greet();
这段代码将会报错,原因是作为单独调用,没有重新绑定this;按照以往,我们可以在构造时重新绑定this:
this.greet = this.greet.bind(this);我们尝试编写一个装饰器来替代这种写法:
function bound(originalMethod: any, context: ClassMethodDecoratorContext) {
const methodName = context.name;
if (context.private) {
throw new Error(`'bound' cannot decorate private properties like ${methodName as string}.`);
}
context.addInitializer(function () {
this[methodName] = this[methodName].bind(this);
});
}在context中我们可以给其中的addInitializer函数创建一个回调,(addInitializer函数可以允许我们将对应的逻辑添加在构造函数之前),将绑定this的操作更新上去,此时我们可以将bound函数作为装饰器给greet方法:
@bound
@loggedMethod
greet() {
console.log(`Hello, my name is ${this.name}.`);
}它们的调用顺序是相反的,即先装饰原有方法并修饰结果。也可以将装饰器放在同一行:
@bound @loggedMethod greet() {
console.log(`Hello, my name is ${this.name}.`);
}和以前一样,也可以给装饰器函数传递参数,在其内部返回的函数将构建成为一个闭包,比如:
function loggedMethod(headMessage = "LOG:") {
return function actualDecorator(originalMethod: any, context: ClassMethodDecoratorContext) {
const methodName = String(context.name);
function replacementMethod(this: any, ...args: any[]) {
console.log(`${headMessage} Entering method '${methodName}'.`)
const result = originalMethod.call(this, ...args);
console.log(`${headMessage} Exiting method '${methodName}'.`)
return result;
}
return replacementMethod;
}
}@loggedMethod("seho")官方建议我们,在编写装饰器时,应该根据自己的需求来编写带类型的装饰器,即尽量保持简单,因为在编写装饰器时如果非要死磕类型的话,那么也会损失可读性,下面是一个通过泛型实现的类型版本装饰器:
function loggedMethod<This, Args extends any[], Return>(
target: (this: This, ...args: Args) => Return,
context: ClassMethodDecoratorContext<This, (this: This, ...args: Args) => Return>
) {
const methodName = String(context.name);
function replacementMethod(this: This, ...args: Args): Return {
console.log(`LOG: Entering method '${methodName}'.`)
const result = target.call(this, ...args);
console.log(`LOG: Exiting method '${methodName}'.`)
return result;
}
return replacementMethod;
}ts5中也对const做出了调整,在以前推断类型时,通常会选择一个更通用的类型,比方说我们需要取record的key,那么会被默认推断为string;在之前的开发过程中也时常会想获取到具体的字面类型,通常会在推断之后加入const,比如我们回忆一下const断言的经典使用场景:
const x = 'x';
let y = 'x'; // stringlet y = 'x' as const; // string默默吐槽一句,官方说有时候会忘记as const断言,然后提供了一个我个人认为更复杂的写法:
type HasNames = { names: readonly string[] };
function getNamesExactly<const T extends HasNames>(arg: T): T["names"] {
// ^^^^^
return arg.names;
}
// Inferred type: readonly ["Alice", "Bob", "Eve"]
// Note: Didn't need to write 'as const' here
const names = getNamesExactly({ names: ["Alice", "Bob", "Eve"] });给类型前面挂一个const,这样推断出来的对象key值才是具体的(不做任何讲解,我觉得我一辈子也用不到这个东西hh)
{
"compilerOptions": {
"extends": ["a", "b", "c"]
}
}在以前,枚举有2种类型,一种是数字枚举,一种是文本类型枚举,它们是不能混用的。但是在ts5中将它们进行了融合,换句话说此时枚举其实就是它的成员类型的联合,并且初始化枚举时,可以是常量也可以是一个表达式:
enum E {
A = 10 * 10, // Numeric literal enum member
B = "foo", // String literal enum member
C = bar(42) // Opaque computed enum member
}那么此时E的类型就是E.A | E.B | E.C;值得注意的是我们应用的常量必须事先声明,否则也会报错,比如:
enum E {
a = b,
}
const b = 1简单的说对于现代捆绑器而言,我们都已习惯了在相对导入下不用编写文件后缀,但是在ts之前没有支持,ts5新增了一个模块查找规则,可以帮助我们使用现代捆绑器时,直接编写如下的代码:
import * as utils from "./utils";{
"compilerOptions": {
"target": "esnext",
"moduleResolution": "bundler"
}
}同时,与之相关,还有一批和此功能类似的配置项更新:https://devblogs.microsoft.com/typescript/announcing-typescript-5-0-beta/#resolution-customization-flags
export type * from "mod"export type * as ns from "mod"这块我不咋用,因为我捆绑ts程序好像好多年都不用tsc了,这个更新大家就主要过个眼熟吧:
大概就是,算法,数据结构,包体积有了显著的升级,不管是安装速度还是使用速度上,相较于4.x版本有个幅度较高的升级。我简单整理了一下ts的优化方案:
有网友说对此次的更新不满意,认为这没有breakchange,版本号变更到5.0是不妥的,我个人感觉不管是新的模块查找规则,还有枚举,面向更现代的es等等更新都可以算的上是5.0;等过段时间稳定之后,我已经迫不及待的想使用5.0啦。