分类 前端 下的文章
简单聊聊Rust和JavaScript同时存在的精度问题
最近学习rust的时候,了解到rust的浮点数实现是和js是一样的, 也就导致了我们在js上遇到的精度问题, 在rust同样也能遇到.
首先我们来理清, rust的默认浮点类型是f64, 而js由于和其他语言不同, 无论是整数和浮点数都是number类型, 也是64位固定长度, 也就是标准的双精度浮点数,
双精度浮点数(double)是计算机使用的一种数据类型,使用 64 位(8字节) 来存储一个浮点数。 它可以表示十进制的15或16位有效数字,其可以表示的数字的绝对值范围大约是:-1.79E+308 ~ +1.79E+308 [1] 。
既然2种语言底层的标准都是一样的, 都是使用了IEEE 754标准中的double精度, 那我们就直接使用大家熟悉的js来做demo.
为什么使用double精度标准
对比单精度标准来说, 虽然double精度占用比单精度高(8byte > 4byte), 这也就间接意味着cpu在处理上, 单精度会有优势, 但是单精度的致命缺陷就是有效数少而且范围也会更小, 总的来说适用性略低, 而且在现代cpu来说, 处理速度上基本是可以忽略不计的.所以在rust中默认的浮点数类型就是f64, 如果有需要就选择f32(单精度)
double精度如何存储
直接从wiki上抄一张图下来

- 符号位:1 位 (+, -)
- 指数:11 位 (次方)
- 有效位数精度:52 位
运算过程
我们通常会用十进制来表达浮点数, 但是我们rust/js底层都是用二进制实现浮点数类型的, 比如说我们写一句这样的代码:
var a = 0.1;在我们程序员眼中它可能就是绝对等于0.1的, 但是在内部实现中, 它需要转换为二进制, 但是在二进制中就是无限精度类型, 也就变成了下面这样:
0.1 -> 0.0001 1001 1001 1001...(1100循环)
但是由于我们底层的标准, 有效位数的精度是52位, 我们在做浮点运算的时候, 多余的数字都会被截断, 所以在js从二进制转换为十进制之后, 就不是我们预想的答案了(在一定精度结果是对的)
, 同理在rust/js中我们也不要使用浮点数做比较, 因为是一个危险不受信赖的计算结果, 也希望精度问题能够引起大家重视, 因为有很多危险的事件是由转换精度触发的:
对于Ariane 4火箭的工作代码在Ariane 5中被重新使用,但是Ariane 5更高速的运算引擎在火箭航天计算机中的算法程序中触发了一个bug。该错误存在于将64位浮点数转换为16位带符号整数的程序中。更快的运算引擎导致了Ariane 5中的64位数据要比Ariane 4中更长,直接诱发了溢出条件,最终导致了航天计算机的崩溃。首先501航天飞机的备份计算机崩溃,然后0.05秒之后,主计算机也崩溃了。这些计算机崩溃直接导致了火箭的主要处理器使火箭的运算引擎过载,同时导致火箭在发射40秒后解体破碎。
顺带提一句, rust中对于整型有溢出处理, 在release环境下, 会按照补码循环溢出的规则去解决, 但是这仍然会造成结果不一致的错误.
如何解决
rust: 我不知道咋解决, 我才学rust
js: 大把的精度库, 最流行的方案就是底层使用string了, bignumber.js, 就可以避免浮点数陷阱;
关于框架(vue.js/sword.js)设计中的“权衡”
在这篇文章之后,我会经常发布一些关于框架设计/架构的一些文章,因为这将作为我的读书笔记,我最近在看一些书比如《vue.js设计与实现》和《前端架构入门和微前端》;我简单介绍一下这两本书,希望对你们有所帮助,首先前端架构这本书一直是我的床头书但是目前对我的工作帮助并不大,因为它比较偏理论个人认为,如果你有耐心并且非常愿意入门前端架构,这本书是一个非常不错的入门书籍;其次就是vue.js设计这本书是最近前端圈的网红书,如果你已经使用过了vue3一段时间了,想精通/深入了解vue3,那么这本书将会带你从设计到实现理清楚vue的所有脉络!
前言
我最近在写我人生中的第一款框架,尽管没有任何含金量,而且这种低级的作品居然是出自一个有着3年开发经验的程序员之手,我还蛮不好意思的;在写这款框架我犯了很多错误和技术债,由于前期没有很好的规划功能以及模块,导致走了不少弯路,而且没有设计框架的经验,我经常会把一个功能放到编译时还是运行时而苦恼,同样我会时常考虑用户的习惯,去联想其他后端框架,导致在框架API设计上有点四不像的感觉。无论如何这款框架再丑也是自己生的,相信不久之后就会和大家见面了,所以我这篇文章将结合我设计的sword.js和vue.js给大家好好聊一聊框架中如何权衡某些事情。
什么是权衡
我们在讲比如vue.js这一类框架时,其中的每一个模块并非独立的,而是互相依赖和制约,框架作者需要有着全局的把控才能更好的扣细节做优化,拆分...那么想象一下当我们要设计一款前端视图层框架的时候,我们需要首先考虑范式,它是声明式的还是命令式的呢,再比如说如果在框架中做hmr底层实现,甚至是构建工具,webpack/rollup/esbuild?可见我们要遇到的选择都太多太多了,那么这就是“权衡”的艺术,框架中的每一个地方,或者说我们在平时写业务的时候,我们都需要去考虑更多东西,这就是权衡。
声明式和命令式
我们从原生js开始说起,如果我想要给一个dom绑定一个点击事件(我全部用伪代码写):
const e = document.querySelector("#app");
e.innerText = "foo";
e.addEventListenner('click', () => {
alert("hello foo")
})这就是典型的命令式代码,代码的执行方式是可预期的,因为都是由开发人员自己编写的每一步操作,但是这就遇到一个很难的问题了,当程序越来越大,我们有多个dom需要绑定点击事件,就要获取n次dom并且一一绑定,这无疑是一种痛苦。那么声明式呢,它可以解决命令式的一些什么问题呢?
<div @click="() => {}" id="app">
</div>如果你使用过vue.js,那么你肯定写过n个这样的代码,我们只给click提供了一个函数,我们并不关心vue是如何获取dom并且绑定点击事件的,我们只需要关注结果就可以了,但是不可否定的是,在vue内部的实现中一定是命令式的,而暴露给用户却是声明式的。那么关乎性能它们谁更好,答案当然是可以预想到的,命令式的代码有着不可替代的性能:
e.innerText = 'update text';在命令式代码中只需要写这一句就可以了,但是如果是声明式代码,我们需要找出新dom和旧dom之间的差异,然后再动态修改text(调用上面这个代码),所以由此得知,尽管声明式代码的性能不如命令式,但是为了更好的维护,我们需要做的就是权衡(既然性能有差距,我们就往可维护性上靠,并且尽可能的优化diff算法,让性能无限接近命令式代码)。
虚拟dom的性能
刚刚我们讨论了声明式和命令式的区别,那么虚拟dom如果你使用了vue.js就一定不陌生,而且它是每个面试官都喜欢问的(我也不知道为什么喜欢问,感觉没啥技术含量)。那么虚拟dom就是为了能够更好的给vue进行diff而出现的,我们要比对如下2行代码:
<div @click="() => {}" id="app">hello foo</div> // old
<div @click="() => {}" id="app">hello bar</div> // new如何用最小的性能消耗找出它们的差异呢?就是虚拟dom,我们在之前说过声明式和命令式代码天然的差距(虚拟dom更新不会比js dom api性能更好),但是事实上99%场景都很难写出绝对优化的命令式代码,但是声明式代码我们可以很轻松的写出来相对还不错的代码。我们为了了解虚拟dom,需要知道我们上述提到的js dom api是什么,要么是createElemnt或者innerHTML,所以我们就用虚拟dom对比一下这两个api的差异。
innerHTML vs 虚拟dom
innerHTML是我写jquery/jsp时的噩梦,因为在新手时期为了构建一个html字符串,我每天半夜调试屎山项目的html字符串,这个过程非常痛苦:
const html = `
<div>
<span>innerHTML</span>
</div>
`
dom.innerHTML = html;js新手小白都知道,dom操作的效率和js层面的计算是不能比较的,差距非常大,为了页面的展示,需要把html字符串转成dom树,然后再执行innerHTML; 反观虚拟dom创建页面需要2步:
- 把我们的模板代码转换成js对象
- 无限递归对象创建真实dom
这么一看,好像innerHTML更直接,而且html字符串转成dom树是dom层一次性且“高效”的运算,所以说虚拟dom创建页面的性能是不如innerHTML的,但是更新页面,虚拟dom的优势就显示出来了,首先innerHTML不仅会对html字符串进行运算,还会把之前的旧dom销毁,然后创建一个新的dom(恨人啊);虚拟dom只需要创建一个新的js对象再与旧的虚拟dom进行比对,哪里有变化就变更哪里!虽然说虚拟dom多了一个diff的操作,但是终究是js层面的运算是很快速的;当页面越来越大,而innerhtml必定都是全量更新,性能也会随着内容变多,和虚拟dom差距越来越大。
粗略比较三个方式的创建&更新技术
- 性能:原生JS > 虚拟dom > innerhtml
- 综合可维护性和性能以及心智负担权衡之下,虚拟dom是一个不错的选择。
运行时和编译时
我们作为框架的作者,希望程序是如何运行的,我们还是用vue.js举例子,刚刚我们讲了虚拟dom,但是却不知道虚拟dom这个js对象是什么样子,我们可以通过这个部分把虚拟dom重新梳理一下:
const obj = {
tag: "div",
children: [{
tag: "p",
children: "hello bar"
}]
}这就是一个虚拟dom对象,描述了每个node的信息以及每个子node的信息,我们如果要实现render方法,就需要对虚拟dom对象进行递归,我们简单实现一下:
const obj = {
tag: "div",
children: [
{
tag: "p",
children: "hello bar"
}
]
};
const render = (obj, root) => {
// 创建一个父节点
const element = document.createElement(obj.tag);
if (typeof obj.children === "string") {
// text节点
element.appendChild(document.createTextNode(obj.children));
} else if (obj.children) {
obj.children.forEach((e) => {
// 如果有多个子节点,就递归创建
render(e, element);
});
}
root.appendChild(element);
};
render(obj, document.body);
这样我们就完成了一个在运行时环境可以完美运行的render,用户可以使用render对页面进行创建元素,但是没有用户愿意每天写这种破数据结构的,所以就肯定要用到编译的东西帮助我们把模板语法转换成数据结构,这个时候就是编译时+运行时,所以vue大多数情况也是这样做的,通过vite/vue-cli对单组件文件进行编译。那么同理既然可以有纯运行时,那么就有纯编译时的东西,可以把我们的模板语法编译成命令式的代码,比如这样:
<div @click="() => {}" id="app">hello foo</div> // old转换成
const e = document.querySelector("#app");
e.innerText = "foo";
e.addEventListenner('click', () => {
alert("hello foo")
})没有虚拟dom,没有diff,only compile!! 这也是svelte.js在做的很酷的事情。所以作为框架设计者关于运行时和编译时我们需要有自己的权衡,虽然vue.js是运行时+编译时,但是在编译时会提取内容,看看哪些内容是永远不可变哪些又是可变的,然后这部分会在运行时再次做优化。所以关于运行时和编译时,没有绝对的好也没有绝对的坏,还是看框架定位和作者自己的权衡了(佛系不引战)。
关于sword.js所做的权衡
如果还不清楚sword.js是做什么的,你可以看看以前的文章,简单的就是说一个nodejs框架,框架中自然就是拥有运行时和编译时,一个framework-core,一个cli。在sword.js中有一个蛮好玩的功能就是,ts运行时检测,这个技术的大概的原理就是,分析ts的类型生成一份schema,然后会有一个函数去比对对象和schema是否吻合,如果匹配成功,那么就算校验通过,这个技术用到参数校验特别好,比如这样:
export interface ReqParams{
title: string;
name: "小红" | "小蓝"
}
const obj = {
title: "test',
name: "小红"
}
validate(obj, schema); // 这里的schema就是interface转的json对象那么我在实现这个功能的时候,分2步走,第一个就是生成schema,第二个就是校验;我把生成这部分放到了cli的编译层这里,程序会自动读取每一个API下的类型,然后转成一个proto.json,在这个json中,运行时可以去校验这部分的对象是否符合要求。权衡好了运行时该做什么,编译时该做什么,就可以把2个工具的大小大大压缩。
再比如说日志模块,在开发nodejs应用的时候,我们需要core的日志,也需要cli的日志,那么如何在终端表现也是需要权衡的。
结语
今年实在是很少时间写文章,就趁着看书和写框架做一个随心记录,希望你们能看得懂(内容偏水,应该都有看得懂)
我写了一个多平台的状态管理持久化的库
store-persistedstate-killer
EN / 中文
杀手级别的持久化状态管理库
- 可以为多个库提供持久化服务 (vuex, pinia)
- 支持 TypeScript
- 支持 预定义存储驱动 (localstorage, sessionstorage) 以及自定义驱动
- 支持相对安全的存储环境(非明文)
- 灵活的配置且没有副作用
- 对开发友好的状态变更 Log
- 持久化加强功能 (重命名...)
安装
npm i store-persistedstate-killer快速使用
// main.ts
// pinia平台
import { plugins as killer, config } from 'store-persistedstate-killer'
createApp(App)
.use(
createPinia().use((context) => {
killer.pinia.init(context)
killer.pinia.use(context)
})
)
.mount('#app')
Demo

目标
- 用状态管理接管你的 storage,从此无需担心类型,像操作 store 一样操作 storage 即可
- 前端存储不再明文
killer 做的事情
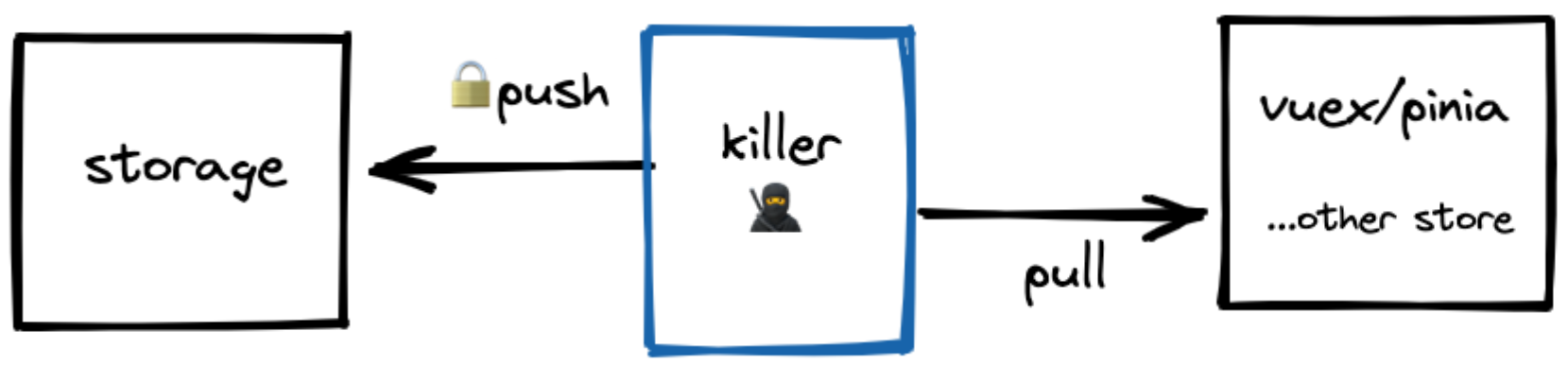
设计
每一个平台的插件你可以单独引入它们,比如你是 pinia 平台,那你仅仅这样引入就可以了
createApp(App)
.use(
createPinia().use((context) => {
killer.pinia.init(context)
killer.pinia.use(context)
})
)
.mount('#app')killer 中每一个插件都包含2个部分, 一个就是 init,一个是 use
init
在应用初始化时,把我们 storage 内容同步到 store 中; 如若发现 store 有,但是 storage 没有的 state,也会执行一次同步。这个过程是双向的。在文档上方就有一个 killer的概要图,我们如果站在状态管理的视角下,可以理解 storage 为远端,双方的交流就可以当作push 和 pull
use
use 是 killer 的核心功能,它可以监听 state 的变更以及 patch 操作,它可以实时地把 state 同步给 storage
如你所见,如果你的业务中,仅仅需要监听 state 然后同步到 storage 这个需求,你也可以仅使用 use 这个插件
如果想看到更多有关平台插件的文档,你可以移步具体的文档中(就在下方)
支持的平台/库
| Platform | Lib | Doc |
|---|---|---|
| pinia2 | ✅ | ✅ |
| vuex4/5 |
核心
killer 为各个平台的插件提供了多个核心,使它们能够正常运转,每一个核心主要负责一个业务,比如说配置,加密,存储
配置
killer 本身自带一个开箱即用的配置,你如果有特殊的需要,可以去自定义它们。在此之前你需要了解各个插件的工作原理,我们以 pinia 举例子。pinia 由一个一个 store 组成,store 由 state,getters,action 组成,所以 killer 仅仅是在useStore()之后才运行的插件,killer 接管了 store 的 state,使之能够持久化到本地存储中;那么在持久化的过程中,我们可能需要做一些重命名, 加密数据等工作...
| 配置名 | 含义 | 类型 | 默认 | 建议 |
|---|---|---|---|---|
| exclude | 排除指定的仓库名 | string[ ] | [ ] | |
| include | 包含指定的仓库名 | string[ ] | [ ] | |
| prefix | 缓存的key前缀 | string | persistedstate-killer- | 建议传入有效的字符串 |
| iv | 加密需要用的iv变量 | string | '' | 可以为空 |
| isDev | 是否是开发环境 | boolean | process.env.NODE_ENV === 'development' | 如果为false将自动加密 |
| storageDriver | 插件预定义的存储驱动 | defineStorageDriver | defineStorageDriver('localStorage') | 支持传入localStorage和sessionStorage |
| store | 对仓库进行详细配置 | Partial<Record<K, StoreConfig>> | 没有默认配置 | |
| defineStorage | 自定义存储驱动 | setItem, getItem, removeItem, iteration | 没有默认配置 | 如果预定义存储驱动defineStorageDriver没有满足你的需求,可以使用这个方法定义新的驱动 |
你的工程中的自定义配置可能就像这样:
import { plugins as killer, config } from 'store-persistedstate-killer'
createApp(App)
.use(Router)
.use(
createPinia().use((context) => {
config.defineConfig<'main'>({
exclude: ['zhangsan'],
include: ['main', 'test'],
isDev: true,
storageKey: 'seho',
store: {
main: {
state: {
hello: {
rename: 'wuyu',
}
}
}
}
})
killer.pinia.init(context)
killer.pinia.use(context)
})
)
.mount('#app')你可以看到, killer 提倡使用 ts 来构建插件,我们可以给 defineConfig 传入一个联合类型,声明需要对哪几个 store 进行操作,此时如果你在编写 include 和 store 配置时,将会有非常棒的类型提示。
| Api | Desc | Type |
|---|---|---|
| defineConfig | 注入配置 | doc |
加密
前端的加密难道没有必要么?确实有人这么说,但是当我们把状态管理的数据明文暴露到 localstorage 中确实不是很好,尽管我们现在都这么做 。我们需要一款易用的加密,不仅可以给 killer 中内部使用,而且还可以暴露给用户,让用户可以加密 api,交换特殊信息?killer 内部使用了crypto-js,默认使用了浏览器ua -> base64, 同时你也可以根
据业务需要指定 key 和 iv。
import { crypto } from 'store-persistedstate-killer'
const _crypto = new crypto()
const message = 'hello, messagehello, messagehello, messagehello, messagehello, messagehello, messagehello, message'
const encryptData = _crypto.encrypt(message)
if (encryptData) {
const decrypt = _crypto.decrypt(encryptData)
console.log('解密结果', decrypt)
} else {
throw Error('加密错误')
}我们可以给构造函数传递一个 ctx
const _crypto = new crypto({
iv: 'asdasdasdasdasdasdasdasd',
key: 'sssaasdasdasdas234234s'
})| Api | Desc | Type | |
|---|---|---|---|
| encrypt | 加密 | ` (data: string) => string \ | null` |
| decrypt | 解密 | ` (data: string) => string \ | null` |
用Graphql+Typescript+Hasura+Vue3+TSRPC构建全栈应用
- 从RestApi到GraphQL
- 如何构建GraphQL
- Hasura是什么
- CQRS
- WEB全栈框架的众神崛起:Nuxt/Next/TSRPC
- 演示在Vue3下与TSRPC,Hasura的畅快开发体验
- 反思: 为现有架构带来的不是新技术栈,而是新思想
- 小结